



Un jeu de dupes

La semaine dernière, je vous parlais de l’intervention qui m’avait le plus marqué lors du “Digital Growth Summit” de Twipe à Bruxelles… et bien cette semaine, je vais faire l’exercice inverse et parler de celle qui m’a le moins impressionnée !
Il s’agit de l’intervention - en visio, depuis New York - de Varun Shetty, le Head of Media Partnerships d’OpenAI. C’est simple, même le représentant de TikTok, qui intervenait un peu avant, avait l’air d’accorder plus de considérations aux médias auxquels il s’adressait. C’est dire ! Mais c’est peut-être simplement le fait d’avoir fait le déplacement…
Varun Shetty a notamment partagé la “philosophie” d’OpenAI en matière d’information. Elle tourne autour de 4 idées fortes, que je traduis ci-dessous :
Créer le kiosque d’information moderne qui concilie expérience utilisateur et intérêts des éditeurs. Associer intention et contexte à un journalisme de haute qualité, produit par des marques dignes de confiance.
Proposer une expérience enrichie avec des liens, qui dirige du trafic directement vers des sources de haute qualité et donne du contexte à la demande initiale de l'utilisateur.
Augmenter la valeur commune pour les utilisateurs et les éditeurs.
Développer une relation à long terme, afin de construire de nouvelles expériences autour des produits OpenAI, tout en nouant des partenariats pour aider les éditeurs à utiliser les outils OpenAI pour construire leurs propres expériences utilisateur basées sur l'IA.

Mon expérience des liens entre “big tech” et médias - j’ai notamment souvenir d’un grand raout de Facebook sur le sujet vers 2012, au moment de la vague des “Social Readers” dans laquelle de nombreux médias s’étaient engouffrés - ne peut que m’inciter à me montrer méfiant face à ces belles intentions…
C’est de toute façon une question de bon sens : il vaut mieux se méfier quand quelqu’un prétend savoir ce qui est bon pour vous…
… d’autant plus quand tout cela masque mal un partage de valeur loin d’être “win-win”. Comme bon nombre de ses prédécesseurs, OpenAI promet en effet aux médias de la visibilité et du trafic, mais pas d’argent. Ou seulement au compte-goutte, pour quelques “grands”, comme Le Monde en France et Prisa Media en Espagne, le Financial Times en Grande-Bretagne, Time, NewsCorp, The Atlantic, Condé Nast, VoxMedia et Hearst aux Etats-Unis…
Au passage, Varun Shetty a rappelé qu’OpenAI n’était pas intéressé par les archives des médias pour entrainer ses modèles - en tout cas pas de façon payante - “[dans ce qui nous guide pour nouer des partenariats] il ne s'agit pas de la taille des archives, du nombre de tokens ou du volume de la bibliothèque, mais plutôt des requêtes que nous recevons.”
Quelques grands médias généralistes sont donc privilégiés, puisqu’ils couvrent au quotidien de nombreux sujets et peuvent nourrir ChatGPT (et demain SearchGPT, dont le lancement grand public serait imminent) avec des données actualisées en continu.
Les autres doivent donc se contenter de quelques miettes, sous forme d’un hypothétique trafic incrémental sur leur site. Je cite : “nous allons d'abord nous concentrer sur la façon dont nous pouvons générer de la valeur [pour les médias] grâce au trafic. Ensuite, nous verrons comment cela évolue et si nous devons investir dans des moyens de monétisation supplémentaires pour nos partenaires. Mais nous pensons qu'il y a ici une opportunité de générer des visites incrémentales significatives auprès de nouveaux publics.”
C’est bien beau, mais c’est oublier un peu vite que la probabilité qu’un lecteur clique sur un lien après avoir lu le résumé d’une information dans ChatGPT (ou Microsoft Copilot) est proche de zéro…
Pour certains médias, y compris de niche, des espoirs de rémunération - hors procédures judiciaires et interventions éventuelles des régulateurs - ne sont toutefois pas à exclure totalement. “J'imagine que dans quelques mois, l’équipe produit reviendra vers moi en disant : ‘voici les principaux marchés clés où nous observons un volume élevé de requêtes d'actualités. Assurons-nous d'avoir des informations solides sur ces marchés”. Les chiffres pourraient indiquer que nous avons besoin de plus de contenus lifestyle sur tel marché spécifique ou plus de contenu en général sur tel autre marché. À mesure que nous avancerons, j’irai donc chercher ces sources afin d’identifier quelles relations commerciales supplémentaires nous devrions établir. “
Je m’arrête là, car toute l’intervention était plus ou moins dans la même tonalité (je grossis le trait, mais l’essentiel du propos était “utilisez nos outils, vous ferez un meilleur travail !” ou encore “vous avez le choix, vous pouvez toujours bloquer nos robots de scrapping, mais vous allez passer à côté de quelque chose”).
Heureusement, nous sommes en 2024, pas en 2012 et plus personne ne peut vraiment être dupe.
Je suis un peu dur, car il y a quand même quelque chose d’intéressant à retenir de cette intervention. Et j’ai presque failli passer à côté. C’est a posteriori, en regardant les clichés que j’avais pris pendant l’intervention, que quelque chose m’a frappé (désolé pour la qualité de la photo) :
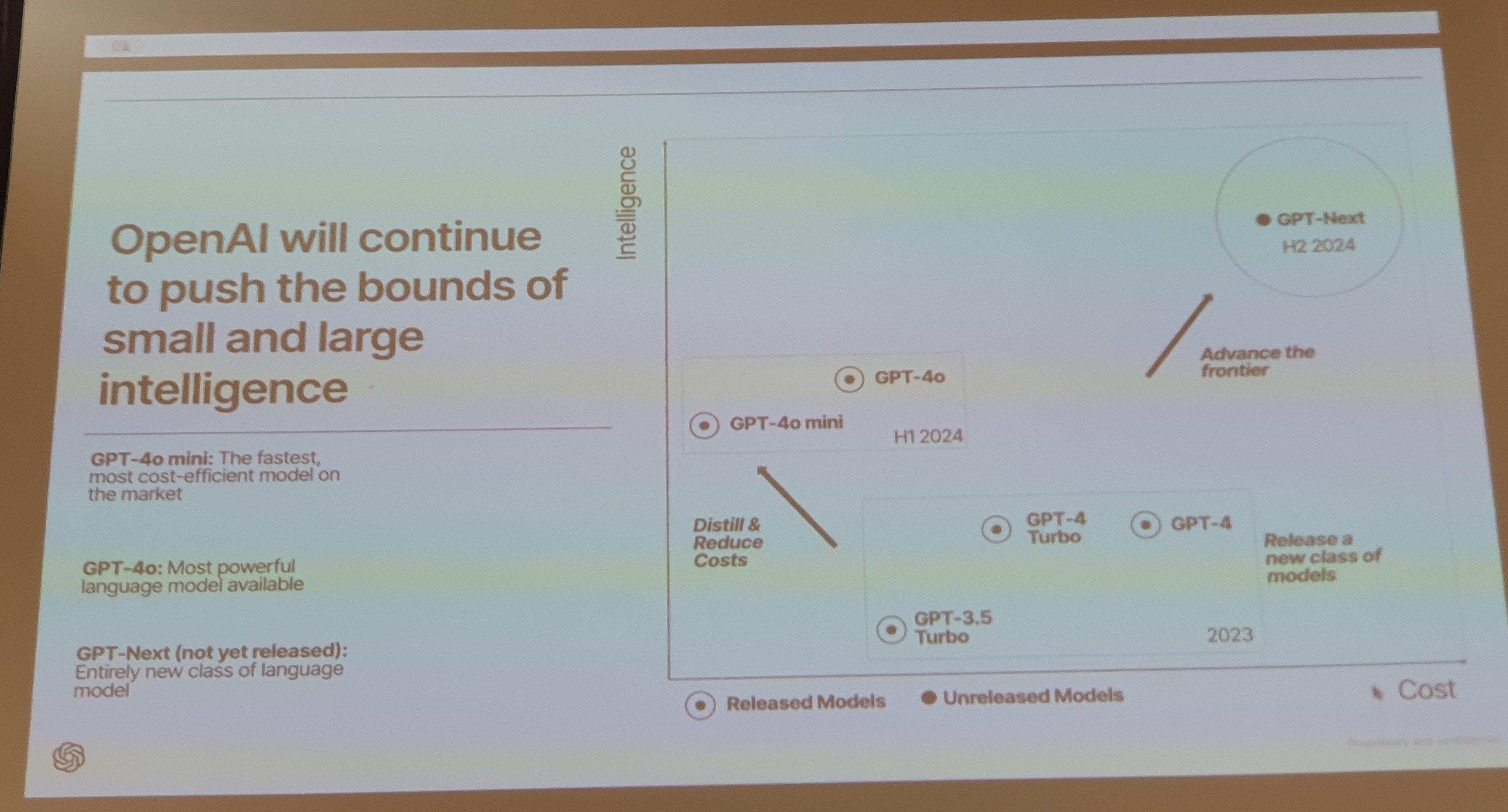
Vous l’avez ?
Dans le coin en haut à droite :

Ce n’est pas tant la présence d’un GPT-Next annoncé pour la deuxième moitié de 2024 (ce qui nous laisse plus beaucoup de semaines avant sa sortie) qui est marquante - l’info avait déjà été ébruitée - que son positionnement relatif par rapport aux autres modèles.
Pour ceux qui avaient commencé à utiliser ChatGPT à son lancement, avec GPT-3.5, le passage à GPT-4 avait marqué un grand progrès. L’arrivée récente de GPT-4o et GPT-4o mini a aussi marqué un cap. Mais là, si on en croit ce schéma, GPT-Next est largement au-dessus en termes d’”intelligence” (même s’il sera aussi bien plus coûteux que ses prédécesseurs…)… Si ce slide ne ment pas, il faut donc s’attendre très prochainement à un nouveau “saut” dans les capacités de l’IA d’OpenAI.
Benoit Zante
Merci Benoît